CLEO AI : Forecasting Solar Panel Soiling with Auto-Regressive Machine Learning.
- Aug 28, 2024
- 5 min read
1. Introduction
Solar energy is a vital and sustainable source of power, but its efficiency can be significantly impacted by soiling—accumulation of dust, pollutants, and debris on solar panels. Accurate prediction of soiling loss is crucial for optimizing energy production and maintenance scheduling. In this report, we delve into the development of an auto-regressive machine learning model that combines historical soiling observations, interpolated weather data, and advanced regression techniques.
2. Model Description

Figure 1: High-level project design
The machine learning model (Figure 1) predicts site-specific soiling accumulation on solar panels across the continental US (currently). It employs a multi-stage approach:
a. Weather Data Interpolation: Spatial Kriging, a geostatistical interpolation method, leverages a K-nearest neighbors algorithm to generate a comprehensive dataset of weather variables (e.g., precipitation, particulate matter concentration) across the target region. This addresses data gaps and provides spatially continuous weather data.
b. Training Data Creation: An autoregressive model integrates the interpolated weather data with historical soiling observations from an extensive network of monitoring stations. This allows the model to 'learn' the complex relationships between meteorological conditions, historical soiling patterns, and subsequent soiling accumulation rates.
c. Soiling Rate Prediction and Simulation: A Random Forest Regressor is trained on the refined dataset. This powerful ensemble method is well-suited for handling non-linear relationships often found in environmental data. The trained model can predict the expected rate of soiling at any given location in the US. An interactive API allows users to input location and timeframe. Using the trained model, it forecasts both soiling rates and precipitation. Finally, a soiling accumulation simulation integrates these predictions, factoring in the mitigating effects of precipitation, to calculate the expected soiling levels on the panels over the specified period.
3. Spatial Kriging model
To accurately predict soiling across the vast expanse of the continental United States, continuous and reliable weather data for any given location and time is essential. We achieve this through a spatial kriging interpolation process that leverages historical weather observations from the Environmental Protection Agency (EPA) network of monitoring stations from 2020-2023. This process focuses on key variables known to influence soiling: precipitation, particulate matter concentrations (PM2.5 and PM10), sulfur dioxide (SO2), and nitrogen oxide (NO2).
At its core, spatial kriging is a geostatistical technique that uses the spatial correlation between known data points to predict values at unknown locations. For each weather variable and each day within our historical dataset, we train a separate k-neighbors model. The k-neighbors algorithm is a simple yet effective tool for spatial interpolation. Essentially, to estimate the value of a weather variable at a new location, it identifies the 'k' nearest neighboring sites with known measurements (where 'k' is a selected number, in our case, k=4). Using a weighted average based on the distances to those neighbors, it predicts the value for the new point. Figure 2 shows the observed data, as well as the interpolated results for PM2.5 with this method.
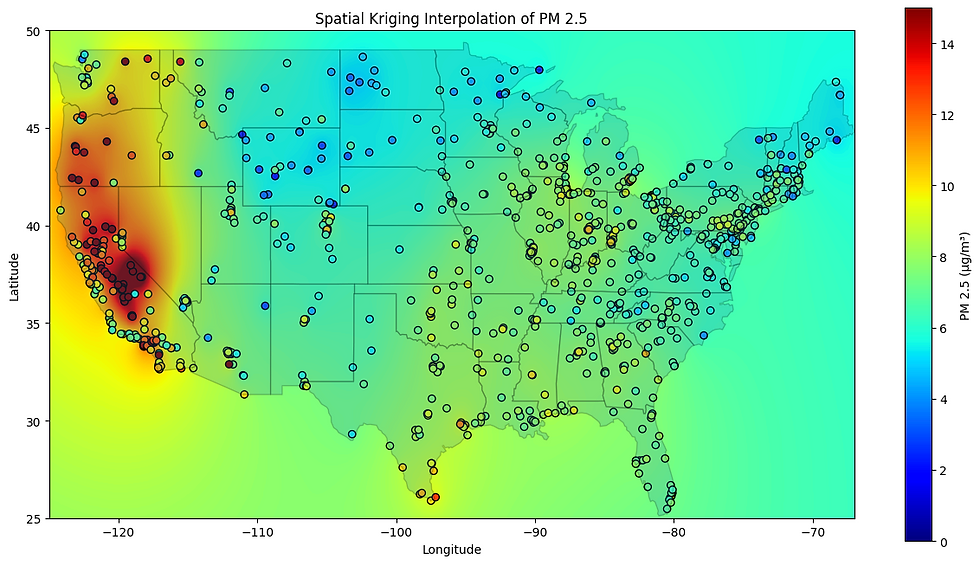
Figure 2: Example of Spatial Kriging
4. Soiling Rate Autoregressive model
With comprehensive interpolated weather data in hand, the next step is to build a model capable of accurately predicting soiling rates. We merge the interpolated weather variables with historical soiling observations collected from hundreds of ARES soiling stations distributed throughout the US. This proprietary Fracsun dataset constitutes a rich resource, containing hundreds of thousands of daily soiling rate observations.
To unlock the complex relationships within this dataset, we employ a Random Forest Regressor. Random forests are a powerful ensemble learning method that combine the predictions of multiple decision trees. They are well-suited for this application due to their ability to handle nonlinear relationships, their robustness to overfitting, and their capacity to identify important features (in this case, the weather variables and other factors that most strongly influence soiling rates).
The model considers several key inputs: interpolated weather data, periodic functions (sine and cosine of the day of the year) to capture seasonal variations, and a trailing soiling rate value representing recent soiling conditions. Importantly, this trailing soiling rate is also interpolated using an additional k-neighbors model. This allows predictions to be extended beyond the existing locations of soiling stations, enabling us to estimate soiling rates across a continuous spatial region.

Figure 3: Feature importances of the Random Forest Regressor
Figure 3 depicts the feature importances for the Random Forest Regressor model we've developed to predict soiling rates. Feature importance is a metric used to assess the contribution of individual features to the overall performance of a machine learning model. In the context of Random Forests, feature importance is typically calculated based on the mean decrease in impurity (or Gini importance) across all the trees in the forest. We see that the 'autoregressive’ feature containing the previous history has the highest feature importance. This suggests that past soiling observations (the autoregressive component) are the most influential factor in predicting future soiling rates. This is followed by Particle Matter data (PM10) and one of the periodicity features (cosine of day of year). The remaining weather variables (PM2.5, SO2 and NO2) appear to have a somewhat lower, but comparable impact on soiling rate predictions according to this model.
The model's performance was evaluated using the R-squared (R²) metric. R² measures the proportion of variance in the observed soiling rates explained by the model's predictions. An R² of 0.678 indicates that the model accounts for 67.8% of the variability in actual soiling rates. This suggests a moderately strong ability to predict soiling rates. Figure 4 shows a scatter plot of predicted vs actual soiling rate, showcasing graphically the predictive ability of the model. The CLEO model is trained on new data every month and thus the R² value is constantly improving.

Figure 4: Training Day 1 Scatter Plot of Predicted vs. Actual Soiling rate on the Testing Dataset
5. Soiling Loss simulation
The final component of the model is a real-time soiling simulation. Through an API endpoint, end-users can specify a location and a date range. The simulation process then iterates through each day within that range, triggering several processes:
a. Data Retrieval: The system loads the appropriate weather interpolation models and calculates the interpolated weather variables and autoregressive feature for the location and date.
b. Soiling Rate Prediction: The soiling rate model predicts the expected rate of soiling accumulation based on the retrieved data.
c. Precipitation Check and Cleaning Event: The system evaluates interpolated precipitation levels. If precipitation exceeds 0.8mm (a threshold determined through prior data analysis), it triggers the start of a cleaning event evaluation. This event partially resets the accumulated soiling loss, with the cleaning effectiveness modeled by a ReLU function for realistic simulation.
d. Soiling Accumulation: When no cleaning event is triggered, the daily soiling rate is added to the previous day's accumulated soiling loss, assuming a linear accumulation process in line with observations from ARES stations.
6. Conclusion.
The auto-regressive machine learning model presented in this report offers a novel approach to forecasting solar soiling across the vast expanse of the continental United States. By leveraging a combination of sophisticated techniques, including spatial kriging for weather data interpolation, historical soiling observations from a proprietary network of ARES stations, and a Random Forest Regressor for soiling rate prediction, the model delivers valuable insights for solar energy asset management.
Through analysis of feature importances, we identified key drivers of soiling loss. Historical data plays a significant role, followed by factors like particulate matter concentrations and seasonal variations. The integrated soiling simulation incorporates a data-driven precipitation cleaning effect, further enhancing the model's realism. It empowers users to investigate soiling patterns for specific locations and timeframes, enabling data-driven decisions regarding cleaning schedules and optimizing energy production.
While the current R² of 0.678 indicates a substantial positive correlation between predicted and actual soiling rates, there is exciting potential for further improvement. As the proprietary network of ARES stations continues to expand, the model will be able to leverage a richer dataset, leading to even more accurate predictions. Additionally, incorporating additional weather variables like wind speed and temperature, alongside continued exploration of feature engineering and potentially even alternative machine learning algorithms, holds promise for further enhancing the model's performance.



Comments